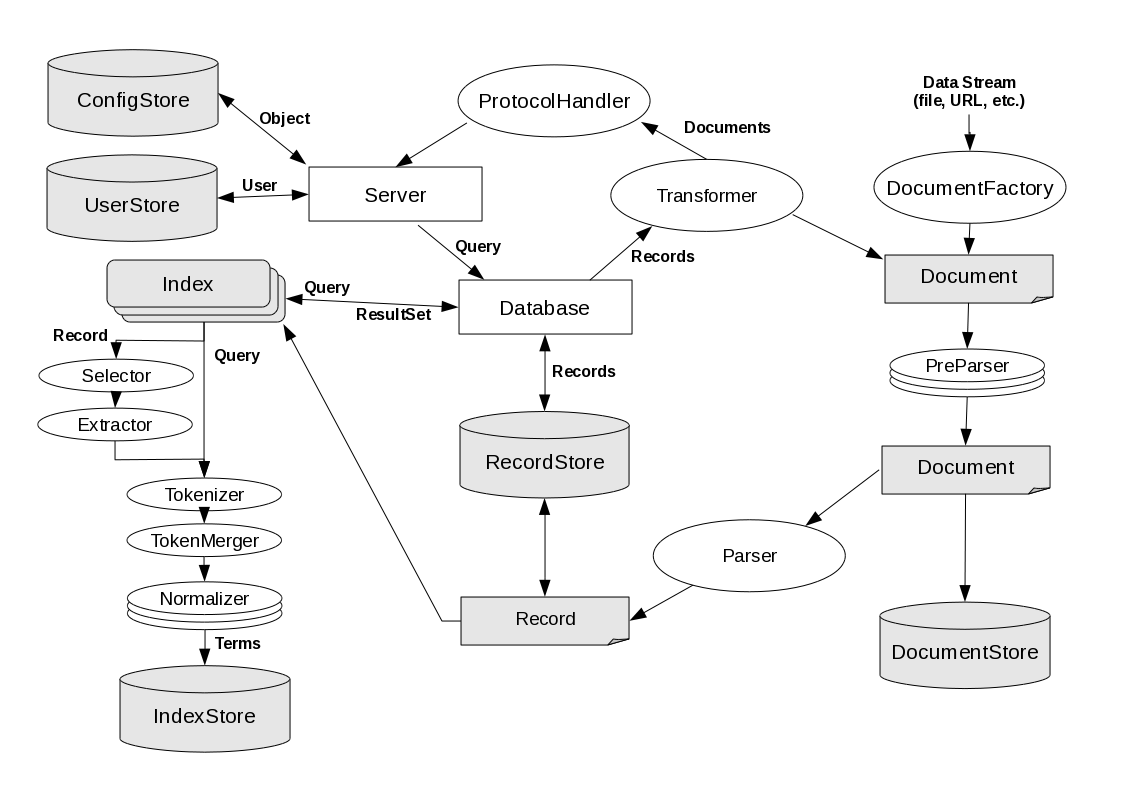
Cheshire3 Object Model¶
Overview¶
Miscellaneous¶
Abstract Base Class¶
Abstract Base Class for all configurable objects within the Cheshire3 framework. It is not the base class for Data Objects :
See C3Object for details and API
Summary Objects¶
Objects that summarize and provide persistent storage for other objects and their metadata.
Server¶
A Server is a collection point for other objects and an initial entry into the system for requests from a ProtocolHandler. A Server might know about several Databases, RecordStore s and so forth, but its main function is to check whether the request should be accepted or not and create an environment in which the request can be processed.
It will likely have access to a UserStore database which maintains authentication and authorization information. The exact nature of this information is not defined, allowing many possible backend implementations.
Servers are the top level of configuration for the system and hence their constructor requires the path to a local XML configuration file, however from then on configuration information may be retrieved from other locations such as a remote datastore to enable distributed environments to maintain synchronicity.
Database¶
A Database is a collection of Records and Indexes.
It is responsible for maintaining and allowing access to its components, as well as metadata associated with the collections. It must be able to interpret a request, splitting it amongst its known resources and then recombine the values into a single response.
DocumentStore¶
A persistent storage mechanism for Document s and their metadata.
RecordStore¶
A persistent storage mechanism for Record s.
A RecordStore allows such operations as create, update, fetch and delete. It also allows fast retrieval of important Record metadata, for use in computing relevance rankings for example.
IndexStore¶
A persistent storage mechanism for terms organized by Indexes.
Not an ObjectStore, just looks after Indexes and their terms.
ResultSetStore¶
A persistent storage mechanism for ResultSet objects.
ObjectStore¶
A persistent storage mechanism for configured Cheshire3 objects.
Data Objects¶
Objects representing data to be stored, indexed, discovered or manipulated.
Document¶
A Document is a wrapper for raw data and its metadata.
A Document is the raw data which will become a Record. It may be processed into a Record by a Parser, or into another Document type by a PreParser. Documents might be stored in a DocumentStore, if necessary, but can generally be discarded. Documents may be anything from a JPG file, to an unparsed XML file, to a string containing a URL. This allows for future compatability with new formats, as they may be incorporated into the system by implementing a Document type and a PreParser.
Record¶
A Record is a wrapper for parsed data and its metadata.
Records in the system are commonly stored in an XML form. Attached to the Record is various configurable metadata, such as the time it was inserted into the Database and by which User. Records are stored in a RecordStore and retrieved via a persistent and unique identifier. The Record data may be retrieved as a list of SAX events, as serialized XML, as a DOM tree or ElementTree (depending on which implementation is used).
ResultSet¶
A collection of results, commonly pointers to Records.
Typically created in response to a search on a Database. ResultSets are also the return value when searching an IndexStore or Index and are merged internally to combine results when searching multiple Indexes combined with boolean operators.
User¶
A User represents a user of the system.
An object representing a user of the system to allow for convenient access to properties such as username, password, rights and permissions metadata.
Users may be stores and retrieved from an ObjectStore like any other configured or created C3Object.
Processing Objects¶
Workflow¶
A Workflow defines a series of processing steps.
A Workflow is similar to the process chain concept of an index, but acts at a more global level. It will allow the configuration of a Workflow using Cheshire3 objects and simple code to be defined and executed for input objects.
For example, one might define a common Workflow pattern of PreParsers, a Parser and then indexing routines in the XML configuration, and then run each Document in a DocumentFactory through it. This allows users who are not familiar with Python, but who are familiar with XML and available Cheshire3 processing objects to implement tasks as required, by changing only configuration files. It thus also allows a user to configure personal workflows in a Cheshire3 system the code for which they don’t have permission to modify.
DocumentFactory¶
A DocumentFactory takes raw data, returns one or more Documents.
A DocumentFactory can be used to return Documents from e.g. a file, a directory containing many files, archive files, a URL, or a web-based API.
PreParser¶
A PreParser takes a Document and returns a modified Document.
For example, the input document might consist of SGML data. The output would be a Document containing XML data.
This functionality allows for Workflow chains to be strung together in many ways, and perhaps in ways which the original implemention had not foreseen.
Parser¶
A Parser takes a Document and parses it to a Record.
Parsers could be viewed as Record Factories. They take a Document containing some data and produce the equivalent Record.
Often a simple wrapper around an XML parser, however implementations also exist for various types of RDF data.
Index¶
An Index defines an access point into the Records.
An Index is an object which defines an access point into Records and is responsible for extracting that information from them. It can then store the information extracted in an IndexStore.
The entry point can be defined using one or more Selectors (e.g. an XPath expression), and the extraction process can be defined using a Workflow chain of standard objects. These chains must start with an Extractor, but from there might then include Tokenizers, PreParsers, Parsers, Transformers, Normalizers, even other Indexes. A processing chain usually finishes with a TokenMerger to merge identical tokens into the appropriate data structure (a dictionary/hash/associative array)
An Index can also be the last object in a regular Workflow, so long as a Selector object is used to find the data in the Record immediately before an Extractor.
Selector¶
A Selector is a simple wrapper around a means of selecting data.
This could be an XPath or some other means of selecting data from the parsed structure in a Record.
Extractor¶
An Extractor takes selected data and returns extracted values.
An Extractor is a processing object called by an Index with the value returned by a An Selector, and extracts the values into an appropriate data structure (a dictionary/hash/associative array).
Example An Extractors might extract all text from within a DOM node / etree Element, or select all text that occurs between a pair of selected DOM nodes / etree Elements.
Extractors must also be used on the query terms to apply the same keyword processing rules, for example.
Tokenizer¶
A Tokenizer takes a string and returns an ordered list of tokens.
A Tokenizer takes a string of language and processes it to produce an ordered list of tokens.
Example Tokenizers might extract keywords by splitting on whitespace, or by identifying common word forms using a regular expression.
The incoming string is often in a data structure (dictionary / hash / associative array), as per output from Extractor.
Normalizer¶
A Normalizer modifies terms to allow effective comparison.
Normalizer objects are chained after Extractors in order to transform the data from the Record or query.
Example Normalizers might standardize the case, perform stemming or transform a date into ISO8601 format.
Normalizers are also needed to transform the terms in a request into the same format as the term stored in the Index. For example a date index might be searched using a free text date and that would need to be parsed into the normalized form in order to compare it with the stored data.
TokenMerger¶
A TokenMerger merges identical tokens and returns a hash.
A TokenMerger takes an ordered list of tokens (i.e. as produced by a TokenMerger) and merges them into a hash. This might involve merging multiple tokens per key, while maintaining frequency, proximity information etc.
One or more Normalizers may occur in the processing chain between a Tokenizer and TokenMerger in order to reduce dimensionality of terms.
Transformer¶
A Transformer transforms a Record into a Document.
A Transformer may be seen as the opposite of a Parser. It takes a Record and produces a Document. In many cases this can be handled by an XSLT stylesheet, but other instances might include one that returns a binary file based on the information in the Record.
Transformers may be used in the processing chain of an Index, but are more likely to be used to render a Record in a format or schema for delivery to the end user.